
- AI
- Technology
AI in 2025: What a Time to be Alive!
A snapshot of AI in 2025 covering key concepts, clarifying misused terms, and practical tips for working with LLMs and navigating the current state of AI in the tech industry.
This post started as a talk I gave at a university, and I figured it was worth turning into something more permanent. It’s a snapshot of AI in 2025 and a foundation for anyone looking to actually work with AI tooling rather than just read about it.
In this short blog series, I’ll cover the key concepts you need to understand, clarify some hugely misused terms, and share practical tips for working with LLMs and navigating the current AI landscape. If you’re just starting out, this should be a solid foundation. If you’re already experimenting, this might fill some gaps. And if you’re deep in the AI mines, you might find something to argue about with me (which I genuinely appreciate!).
AI in 2025
From my point of view, “AI” is in an extremely volatile state, almost as if it was a biotech stock. There are rapid developments, lots of companies are fighting over market shares, and lots of people are fighting for your attention with their latest hot takes and AI that will replace millions. At the same time the AI tooling we get is extremely powerful. It holds great potential for automation, making data and code more accessible, reducing toil and replacing lower-value manual tasks. It is very expensive, especially once you start to scale it, and as we’re moving into a future of increased demand and token costs, knowing where to apply AI tooling will be crucial.
As any honest power user will tell you, commercial AI is also extremely dumb and useless unless you know when and where to use it and no amount of hype posts on social media will ever change this. If anything, the overabundance of professionals hyping up and calling things “AI” has turned AI into a meaningless buzzword, that just means it’s the latest version, like we had “cloud-enabled” and “smart” before.
I’m really fortunate. Kentico decided to go all-in on AI and our focus for the past year has been to experiment with AI tooling, see where it works the best, start integrating it in our internal workflows, and at the same time release realistic, high-value AI product features. We’re not looking to deploy AI everywhere, we’re looking to utilize AI tooling where it will bring the most value out of the end user, be it our internal teams, or a customer working with Xperience by Kentico. If you’d like to read more about Kentico’s AI journey, check out my posts on AI in Kentico in Numbers, Early Lessons in AI Enablement and all the wonderful AI-related posts on the Kentico Community Portal
The Many Faces of AI
This is not an exhaustive list, but I’ve compiled a few things that people could be calling AI even if they’re not necessarily AI-driven at all, plus some example applications:
- Computer Vision - Google Photos tagging your holiday pictures, speed cameras reading your number plate
- Large Language Models (LLMs) - ChatGPT, Claude, you usual suspects
- Recommendation systems - Spotify’s “smart” shuffle, the YouTube algorithm
- Predictive models & Machine Learning Classifiers - fraud/spam detection
- Robotics & Autonomous Systems - manufacturing systems, robot vacuums
- Speech & Audio processing - Siri, transcription tools
- Web automations - dynamically adjusting values based on consumption, websites recognizing things about you
- Analytics services - generally consuming and making data accessible, Google Analytics, error log summaries
- Elaborate control flows in consumer goods - I recently purchased an AI-powered steam iron AMA
While I’d love to extensively talk about my AI-powered steam iron, let’s look at what in my opinion are the core forms of AI that many of us are utilizing and benefiting from.
Computer Vision
What it is: Computer vision is a computer science discipline focused on interpreting and extracting information out of images and videos. Generally it’s treated as a subfield of AI or Machine Learning. In practical terms, it allows computers to “see” and find meaning in clusters of pixels.
What it’s used for:
- Detecting objects and classifying images
- Extracting information from graphs and texts
- Facial recognition software
- Medical imaging
- Self-driving cars
- Manufacturing quality control
- Augmented reality
Speech and Audio Processing
What it is: Historically, Speech Processing has been a subfield of Signal Processing, and it’s now a core part of Artificial Intelligence and Machine Learning. It is focused on modeling sound, turning sound waves into data and using said data to synthesize sound waves. If computer vision allows computers to “see”, then Audio Processing allows them to “hear” and “speak” based on digital representations of sound waves.
What it’s used for:
- Speech-to-text and text-to-speech.
- Voice assistants
- Automatic captions
- Accessibility features
- Call center automation
Large Language Models (LLMs)
What it is: Large Language Models are a subfield of Natural Language Processing (NLP) and Artificial Intelligence focused on understanding, generating, and transforming human language. They are trained on vast amounts of text to learn statistical patterns, relationships, and structure within language.
In practical terms, LLMs allow computers to “read” and “write”, producing text, code, and reasoning-like outputs based on patterns rather than true understanding.
What it’s used for:
- Conversational interfaces and chatbots
- Text generation, rewriting, and summarization
- Code generation and explanation
- Search, knowledge retrieval, and Q&A
- Translation and language transformation
- Document analysis and classification
Pattern Matching ≠ Understanding
This is probably the most important concept in this entire post, so pay attention.
Current AI systems are statistical pattern recognizers. They cannot comprehend, reason, or act with intent and consciousness. This applies to every kind of AI that’s currently available, regardless of how impressive the demos look.
- LLMs -> match linguistic patterns
- Computer Vision -> match visual patterns
- Speech Processing -> match audio patterns.
All of these algorithms correlate patterns with objects or meaning, they just focus on different representations. None of them “understand” in the human sense. They lack grounding; there’s no connection to physical experiences, or any awareness and intention.
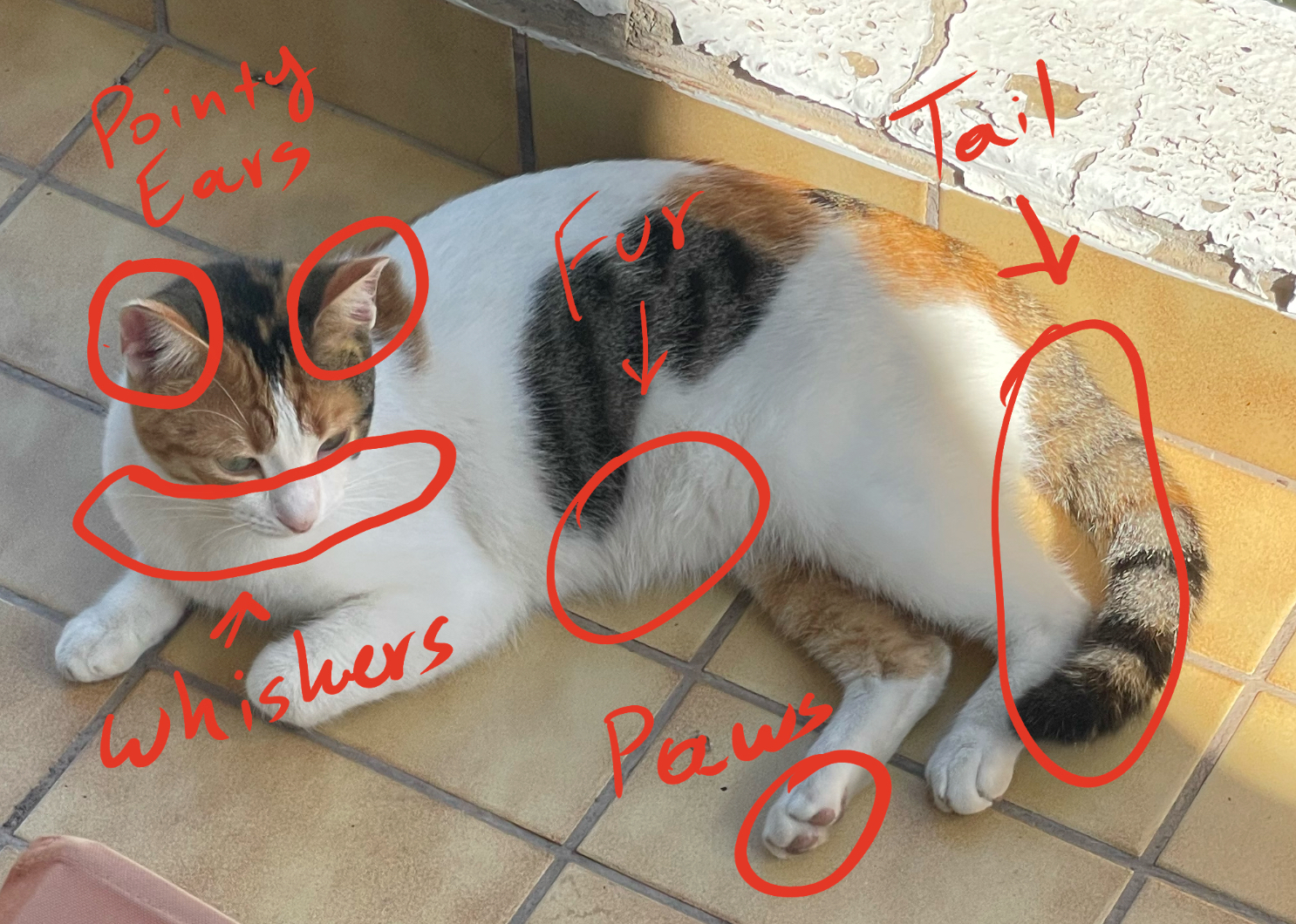
Here’s an example with a cat.
This is Cheese, my stray cat buddy from Athens. Google Photos knows this is a cat and can even specifically recognize these pictures as “Cheese” instead of any other cat.
The CV algorithm has learned to associate “cat” with a set of visual patterns:
- pointy ears
- whiskers
- a furry texture
- a fluffy tail
- paws
Anything that matches these characteristics, will be classified as a “cat”. So let’s take a look at another cat.
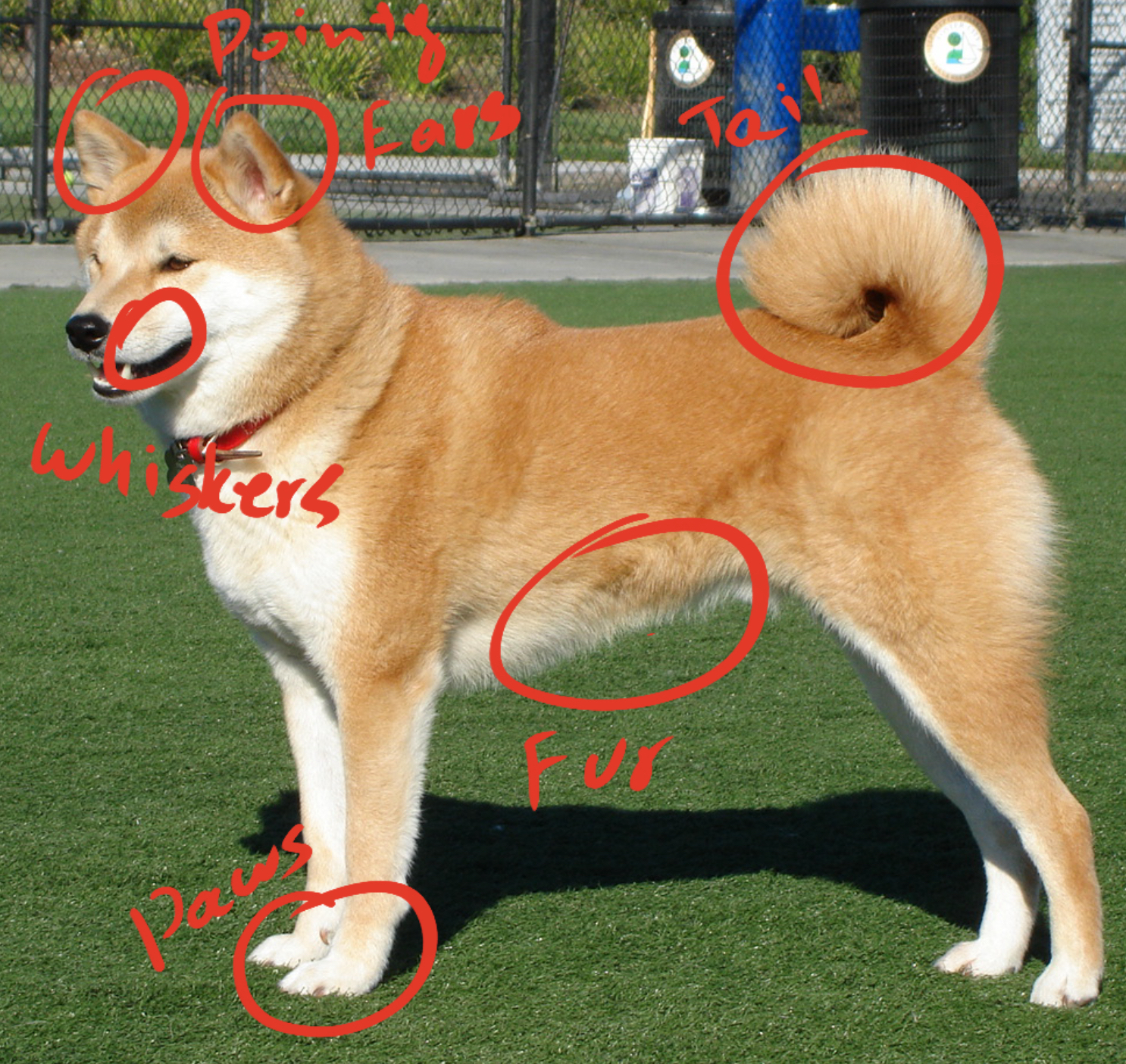
Let’s review:
- pointy ears ✅
- whiskers ✅
- a furry texture ✅
- a fluffy tail ✅
- paws ✅
So this Shiba from Wikipedia is a Shiba Neko (cat) instead of a Shiba Inu (dog).
If the learned patterns overlap enough, a CV model will happily label this as a cat because it has no concept of species at all. It doesn’t know what a cat is. It only knows what cat-shaped pixels look like, and this is a perfect match.
This is why your photo app occasionally thinks your friend’s corgi is a cat, why facial recognition systems have historically struggled with certain demographics, and why self-driving cars have had issues with unusual obstacles. The model isn’t “confused” — it’s doing exactly what it was trained to do. It’s just that pattern matching without understanding will always have edge cases, and those edge cases can range from amusing to catastrophic depending on the application.
Your Results are Only as Good as Your Data
We have a beautiful saying in Greece: “If you make the butt the cook, all you get is crap.” This truly shines in the context of AI. If your data is garbage, all you’ll get is garbage (potentially categorized!).
Models learn patterns based on the data you give them. If the data is biased, incomplete, or incorrect, the model will be too. This isn’t a bug, it’s exactly how these systems work.
Here’s a practical example: imagine you’re training a model to classify customer support tickets. If your training data is 90% complaints about billing and 10% about technical issues, your model will become very good at spotting billing problems and terrible at everything else. It might even start classifying legitimate technical issues as billing complaints because that’s what it knows best. The model isn’t broken; it’s faithfully reproducing the patterns in your data.
Or consider a fraud detection model trained primarily on data from one region. It’ll be great at catching fraud patterns common in that region but might completely miss (or wrongly flag) legitimate transactions from elsewhere. The model isn’t malfunctioning. It’s just never seen those patterns before.
Often, better data will beat a better model. A smaller, well-curated dataset can outperform a massive, noisy one. And even an all-powerful GPAI (General Purpose AI) model will be outmatched by smaller, specialized models trained on high-quality domain-specific data.
Don’t mistake “better” for “specialized” though. Data quality is also affected by recency. Imagine a coding assistant trained only on data up to 2018. It would have no idea about modern frameworks, security practices, or even basic syntax changes in newer language versions. In fast-moving fields, yesterday’s data can be today’s misinformation.
What We’ve Established
Let’s recap what we’ve covered:
- AI is a broad term covering everything from computer vision to LLMs to your steam iron. Know what you’re actually talking about.
- Pattern matching is not understanding. No current AI system comprehends anything. They correlate patterns with outputs. This is true for vision, speech, and language models alike.
- Data quality is everything. Biased, incomplete, or outdated data produces biased, incomplete, or outdated results. No amount of model sophistication fixes bad inputs.
Understanding these fundamentals is crucial because they directly impact how you should work with AI tools. If you treat an LLM like it “understands” your code, you’ll accept garbage outputs. If you don’t consider data quality, you’ll wonder why your AI features are producing nonsense.
Next Time: Actually Using This Stuff
Now that we’ve established what AI is (and isn’t), the next post gets practical. We’ll dig into how LLMs actually work under the hood: tokens, context, prompting. Understanding these mechanics is the difference between getting useful output and getting confidently wrong garbage.
If you’re already using AI tools and wondering why your results are inconsistent, the next post should help. If you’re just getting started, it’ll give you a foundation that’ll save you a lot of frustration.
See you there.